第一部分 绪论
数据与数据库
数据库的特点
- 整体数据的结构化
- 数据的共享性强,冗余度低且易于扩充
- 数据的独立性强
- 数据由数据库管理系统统一管理和控制
- 整体数据的结构化是数据库系统阶段与文件系统阶段的本质区别
- 数据的独立性分为物理独立性和逻辑独立性
数据模型
概念模型
**概念模型是对现实世界的事物符号化的描述,为计算机处理做准备。 **
常用的概念模型是E-R (Entity-Relationship)图 。
数据模型的三要素
- 数据结构
- 数据操纵
- 完整性约束
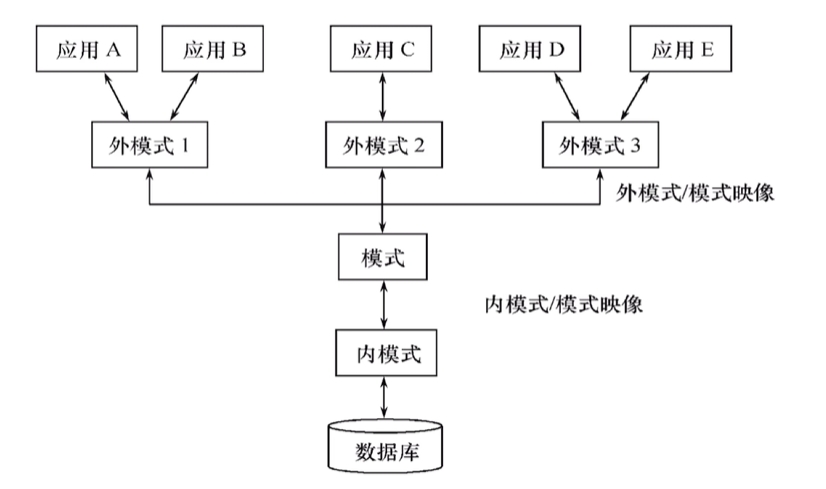
三级模式
外模式(可以有多个)
外模式是用户看到的,不同用户看到的不同,比如老师、学生
外模式 ≠ 视图,但视图是外模式的一种实现方式
可以这么理解:
- 外模式(External Schema / View Schema) 是一个 概念,指数据库为不同用户提供的 个性化、局部的数据视图。
- 视图(View) 是数据库系统里 实现外模式的主要手段之一。
所以:
外模式比视图大,视图只是外模式的具体实现方式之一。
模式(只能有一个)
模式 = 数据库的逻辑结构定义。
也可以说:
模式就是数据库在逻辑层面上的“总体设计蓝图”。
它规定了数据库里有哪些表、每个表有哪些字段、字段类型是什么、主键外键是什么、约束是什么等。

两级映像

常考的题目

第二部分 关系模型
几个重要概念
域
理解成定义域、值域,就是取值范围
笛卡儿积
就是各种组合方式*(离散数学学过)*
码
候选码
某一(个)组属性的值可以唯一标识一个元组,而其子集不行
主码
选一个候选码作为主码

主属性是候选码中的各个属性,不仅仅是主属性中的
任意两个元素的码不能相同
关系的完整性
实体完整性
就是主属性不能是空值
空值是不知道、不存在或无意义的值

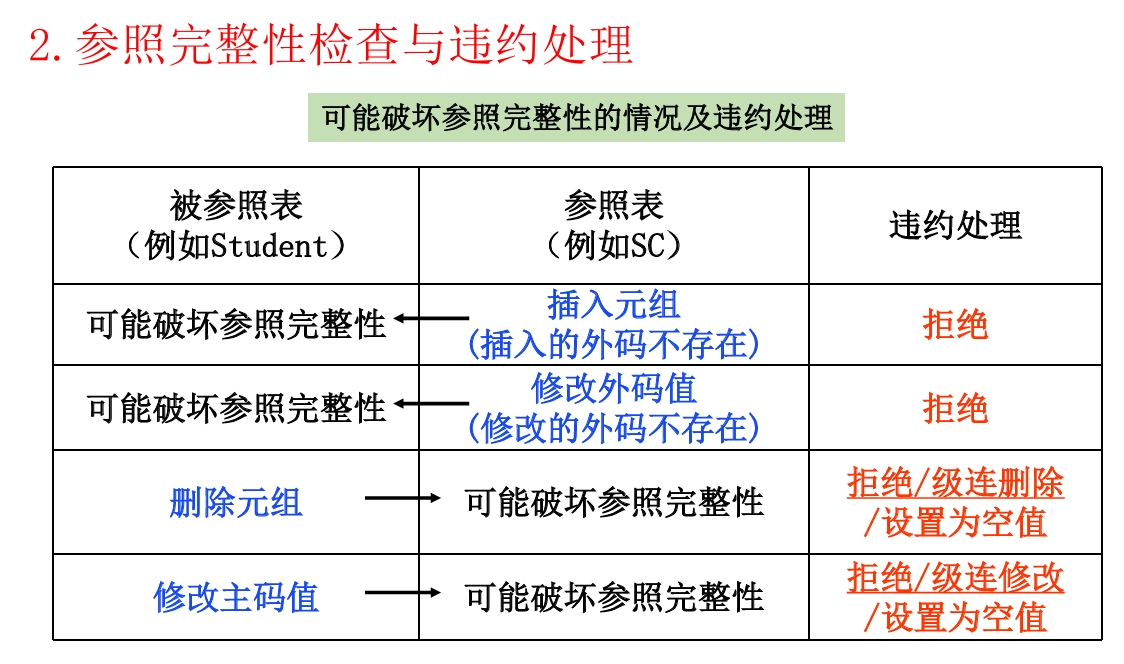
参照完整性
关系与关系之间可能存在引用,如课程、学生、选课三个关系
外码

R参照了S,例如选课表参照了学生、课程两个表
参照完整性约束

就是那个外码,要有的话,必须是真实存在的,比如选课表中,选的那个课必须是有的。
用户定义的完整性
根据需求,用户对数据自行定义的要求
参照完整性违约处理
关系代数(很重要)
以前学过的一些关系运算
并运算
略
差运算
R-S:属于R,不属于S
交运算
略
笛卡儿积
R x S 略
专门的关系代数运算
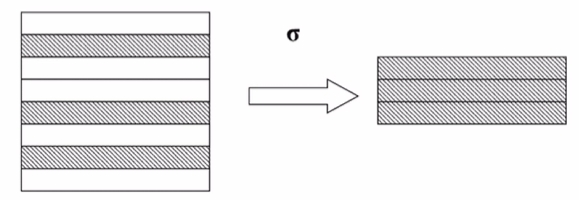
选择

从行的角度筛选,是行的运算
投影
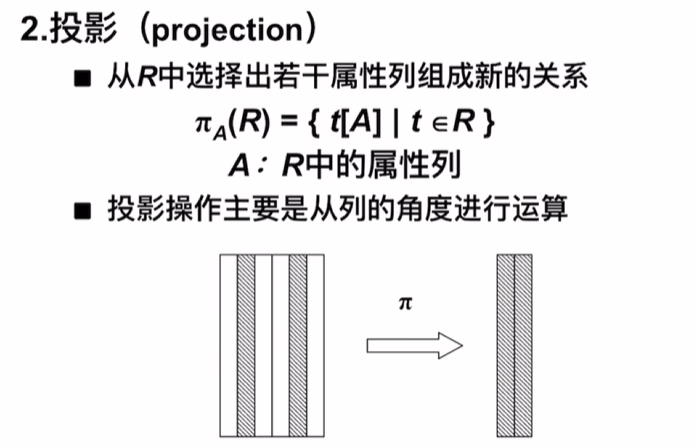
- 投影是从列的角度筛选
- 投影后还可能消除某些元组,实现去重复
连接运算

等值连接
θ为等号“=”
自然连接
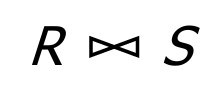
- 省略了连接号底下的比较运算式子
- 自然连接是一种特殊的等值连接
- 自然连接比较的是两个关系中同名的属性组,并且连接后会去掉重复的属性列,比如两都有一个“学生ID”,那最后之后留为一个
悬浮元组
连接时被舍弃的元组:

外连接

除法运算(重要)
项集
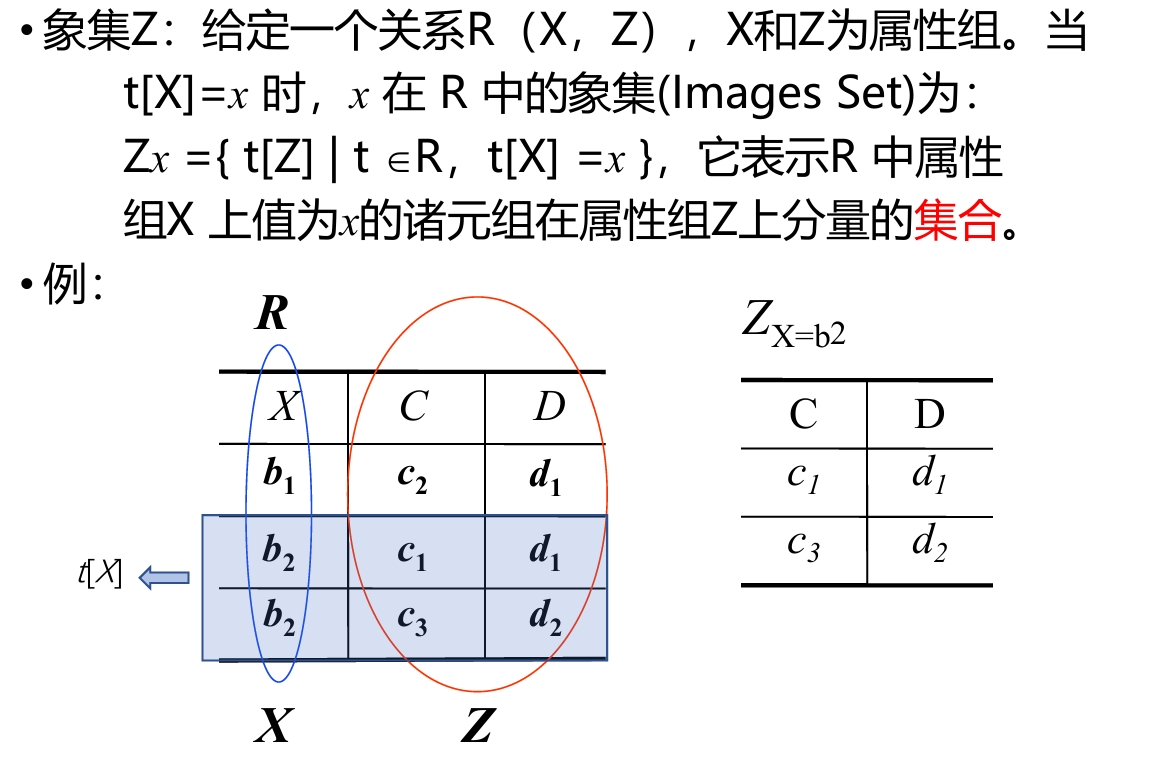
除法
关系代数里的 除法(Division)用于解决这种类型的问题:
找出那些对所有 Y 都满足某个关系的 X。
即:
- 有一个关系 R(X, Y),里面是 (X,Y) 的配对
- 再有一个关系 S(Y),里面是一组 Y
- R ÷ S 的结果,是R中:所有对 S 里的每个 Y 都有配对的 X

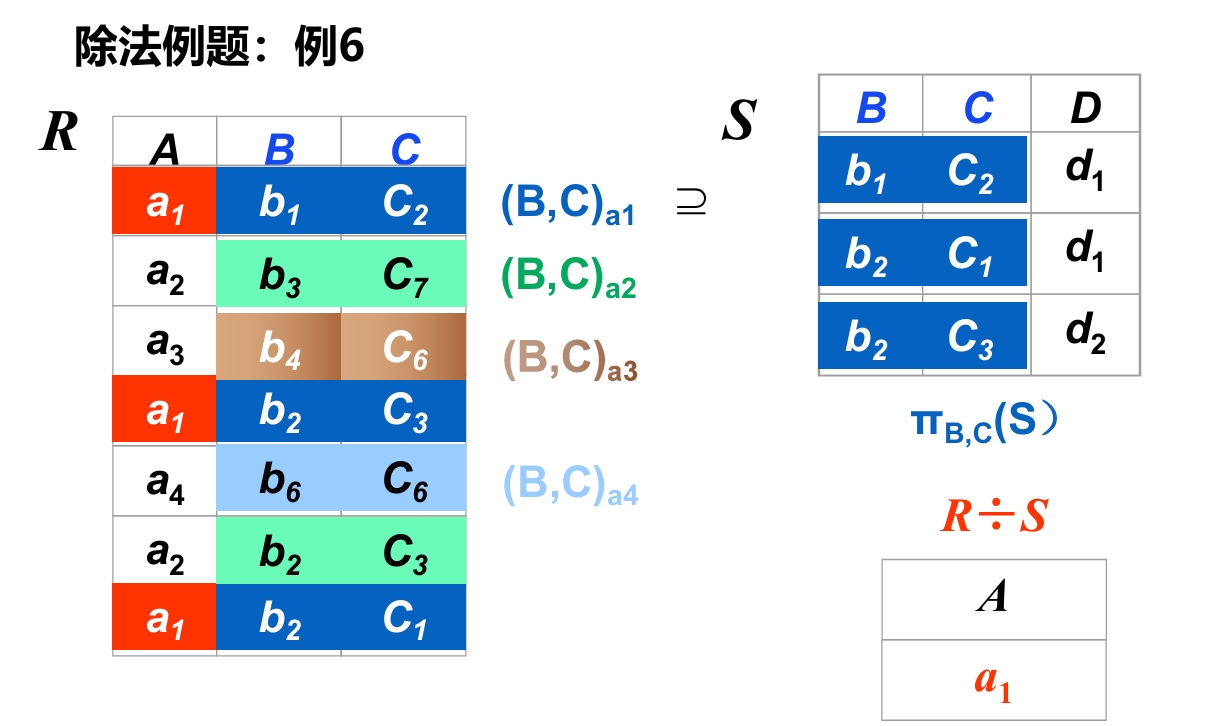
- Y是R和S中共有的属性,R除以S的结果,是R中除去共同属性的属性
- S中,除了共同属性,其它的可以不用管
第三部分 SQL语言
SQL语言特点
- 综合统一
- 高度非过程化
- 面向集合的操作方式
- 以一种语法结构提供多种组合方式
- 语言简洁,易学易用
数据定义DDL
数据库的管理
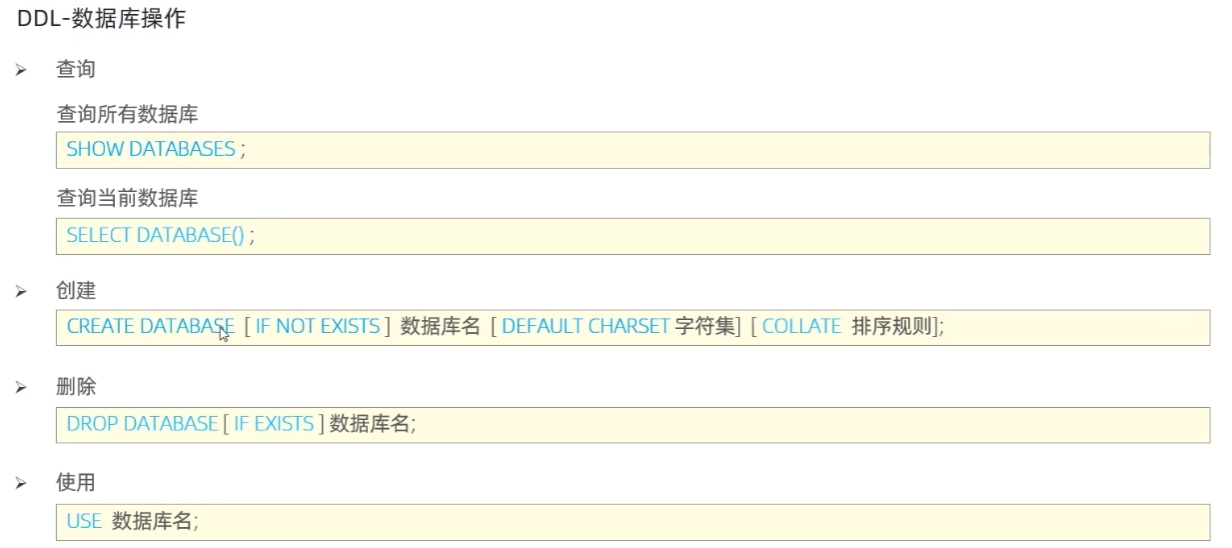
表的管理
查看所有表
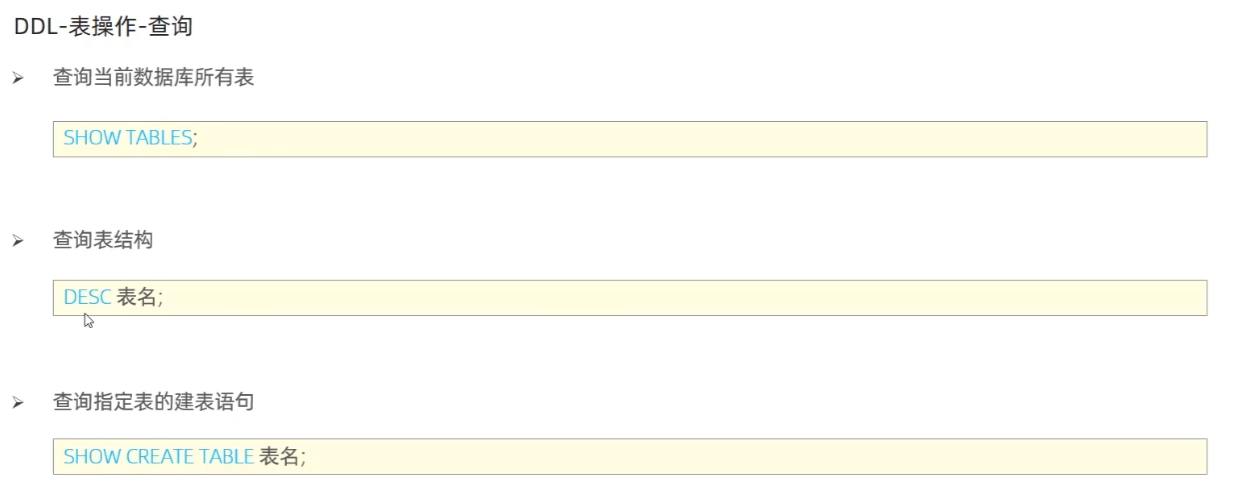
SQL 数据表的创建
CREATE TABLE 表名 (
列名1 数据类型 [列级约束],
列名2 数据类型 [列级约束],
...,
[表级约束]
);列级约束
PRIMARY KEY 主键
NOT NULL 非空
UNIQUE 唯一
DEFAULT 默认值 默认值
AUTO_INCREMENT 自增(MySQL)
CHECK (表达式) 检查约束表级约束
PRIMARY KEY (列名)
UNIQUE (列名)
FOREIGN KEY (列名) REFERENCES 外表(列)
CHECK (表达式)通式
CREATE TABLE 表名 (
列名1 数据类型 [PRIMARY KEY | NOT NULL | UNIQUE | DEFAULT 值 | CHECK(条件)],
列名2 数据类型 [NOT NULL | UNIQUE | DEFAULT 值],
列名3 数据类型,
...
-- 表级约束
[PRIMARY KEY (列名1)],
[UNIQUE (列名2)],
[FOREIGN KEY (列名X) REFERENCES 外表(外列)],
[CHECK (条件)]
);常见数据类型
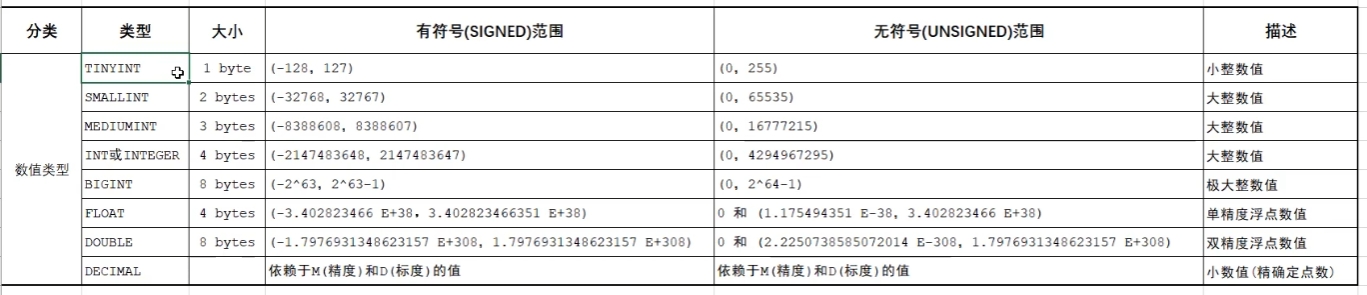
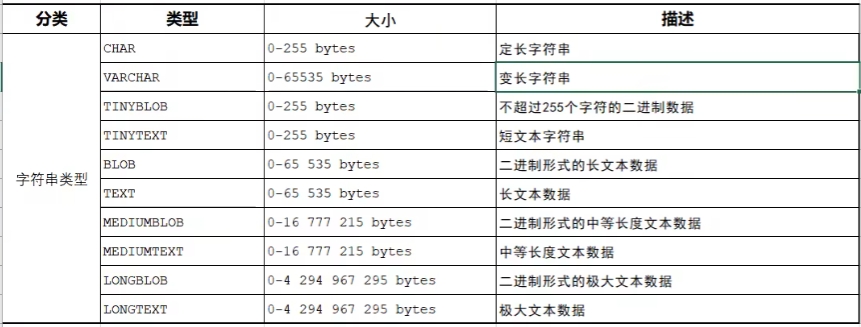

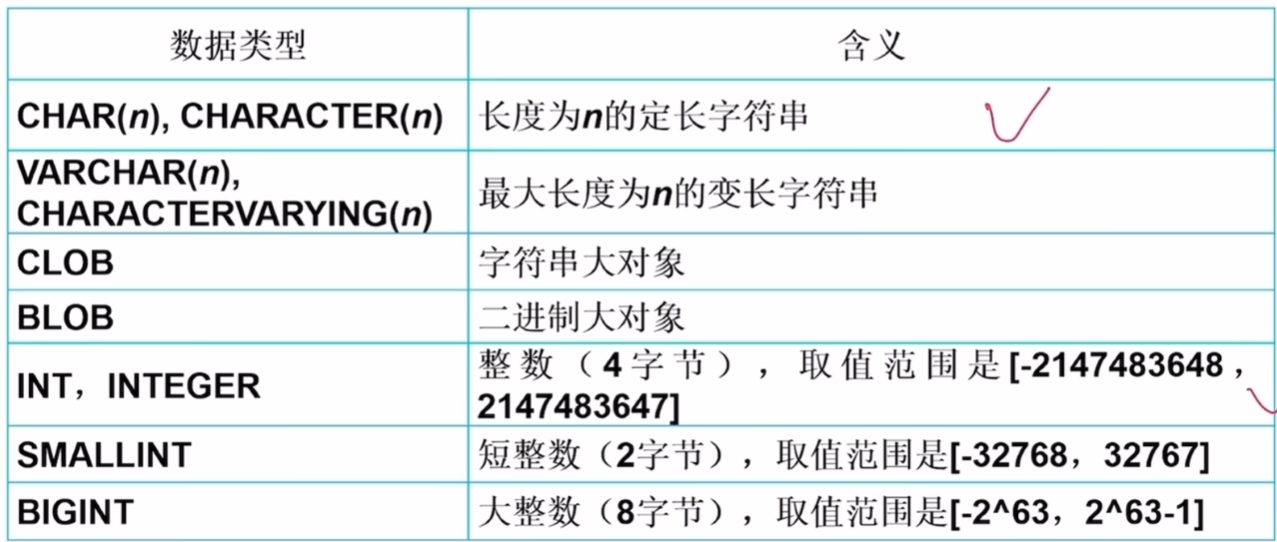
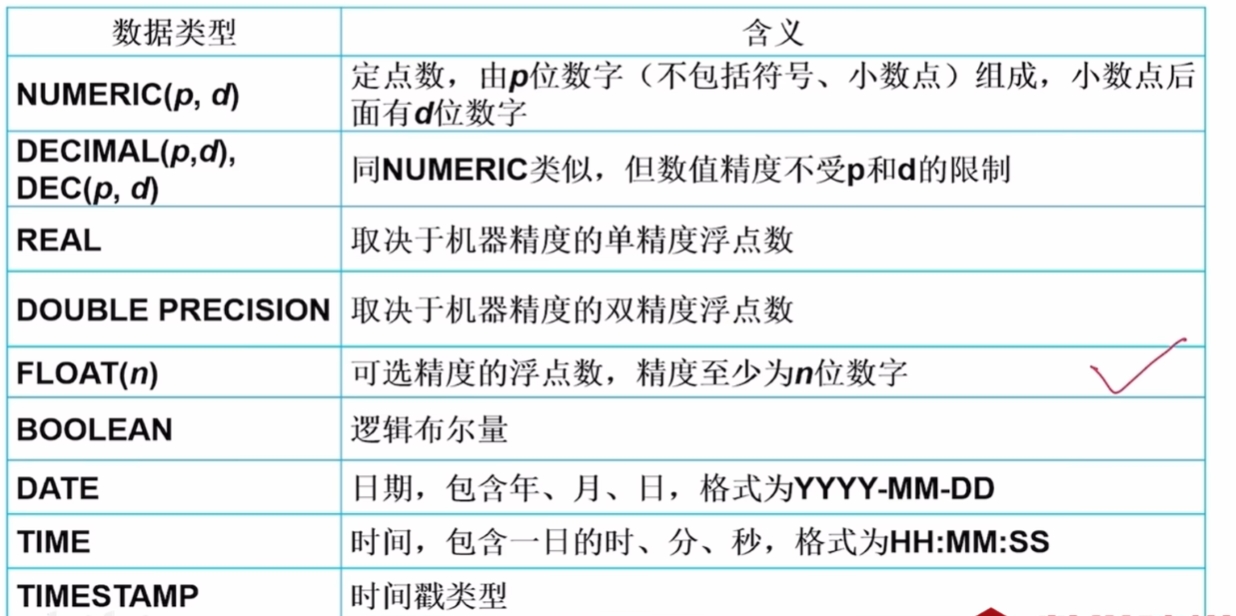
表的修改
修改表名

添加字段

删除字段

修改字段
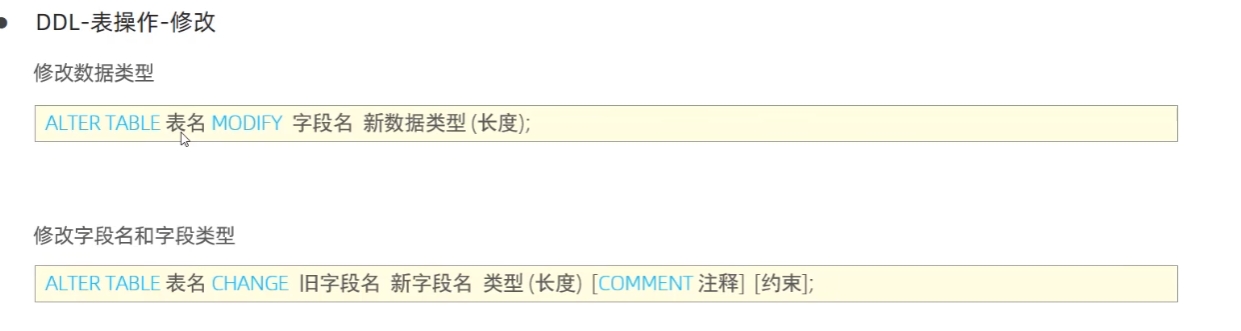
MODIFY COLUMN
ALTER TABLE 表名
MODIFY COLUMN 列名 数据类型 [约束];- 作用:修改列的数据类型、约束(如 NOT NULL、DEFAULT),列名不变。
- 优点:语法简洁。
- 限制:不能改列名。
示例:
ALTER TABLE users
MODIFY COLUMN age BIGINT NOT NULL;这条命令只修改了
age的类型和约束,列名保持不变。
CHANGE COLUMN
ALTER TABLE 表名
CHANGE COLUMN 旧列名 新列名 数据类型 [约束];- 作用:修改列的数据类型、约束,同时可以改列名。
- 优点:灵活,可以改名字和类型。
- 注意:必须写新列名,即使不改名字也要写。
示例:改名字+类型:
ALTER TABLE users
CHANGE COLUMN username name VARCHAR(50) NOT NULL;示例:只改类型,不改名字:
ALTER TABLE users
CHANGE COLUMN age age BIGINT;
- 如果你只是改类型,
MODIFY更简洁;如果要改名字,必须用CHANGE。MODIFY和CHANGE只能修改列级属性(列的数据类型、约束、默认值等),不能直接修改表级约束(如主键、外键、唯一约束、索引、表名等)。
添加唯一约束
方法一:列级创建表时直接加 UNIQUE
CREATE TABLE users (
id INT PRIMARY KEY,
email VARCHAR(100) UNIQUE, -- 列级唯一约束
username VARCHAR(50)
);方法二:表级约束
CREATE TABLE users (
id INT PRIMARY KEY,
email VARCHAR(100),
username VARCHAR(50),
CONSTRAINT uq_email UNIQUE (email) -- 给约束起名字
);方法三:给已存在的表添加唯一约束
ALTER TABLE users
ADD CONSTRAINT uq_username UNIQUE (username);注意:
CONSTRAINT uq_username是约束名,可自定义。
删除唯一约束
MySQL 中唯一约束在内部是 唯一索引,删除方式如下:
方法一:删除索引(最常用)
ALTER TABLE users
DROP INDEX uq_username;方法二:如果没有命名约束名
- MySQL 自动生成的约束名就是索引名,执行
SHOW INDEX FROM 表名;查看索引名,然后再用DROP INDEX。
数据更新 DML
添加 insert into

修改数据 update

删除数据

数据查询 DQL
基本查询

条件查询

like相关
如果 LIKE 模式里本身包含 %、_ 或转义字符本身,需要使用 ESCAPE 子句 或在 MySQL 里加反斜杠 \ 转义。下面给你详细讲清楚。
使用反斜杠转义(MySQL 默认)
SELECT * FROM products
WHERE name LIKE '100\%' -- 匹配包含 "100%" 的字符串\%表示字面上的%,而不是通配符- 同理,
\_表示字面上的_
MySQL 默认反斜杠就是转义字符。
使用 ESCAPE 子句(通用 SQL)
如果你想自定义转义符,可以用 ESCAPE:
SELECT * FROM products
WHERE name LIKE '100!%' ESCAPE '!';!是自定义转义符!%表示字面%- 你也可以用其他字符,比如
~等。
| 情况 | 解决方法 |
|---|---|
匹配字面 % | \% 或 LIKE 'xxx!%' ESCAPE '!' |
匹配字面 _ | \_ 或 LIKE 'xxx!_' ESCAPE '!' |
| 匹配转义符本身 | MySQL: \\,ESCAPE: 需要转义符两次 |
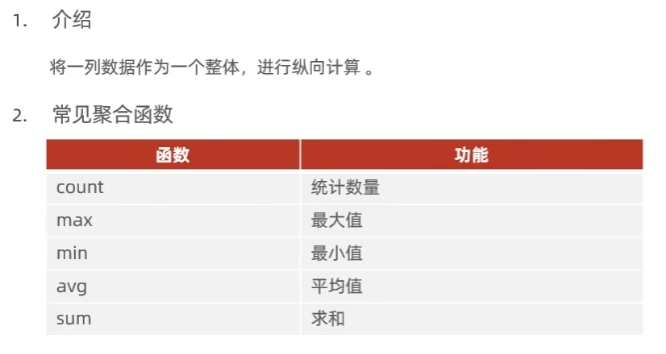
聚合函数
分组查询

排序查询
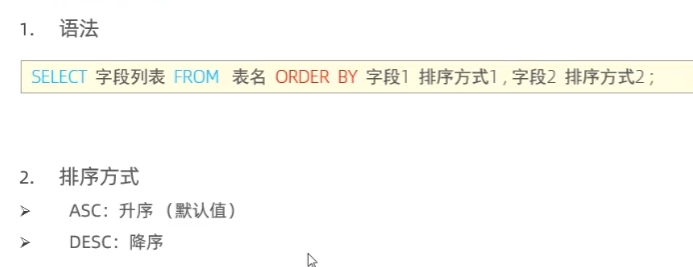
分页查询

DQL语句执行顺序
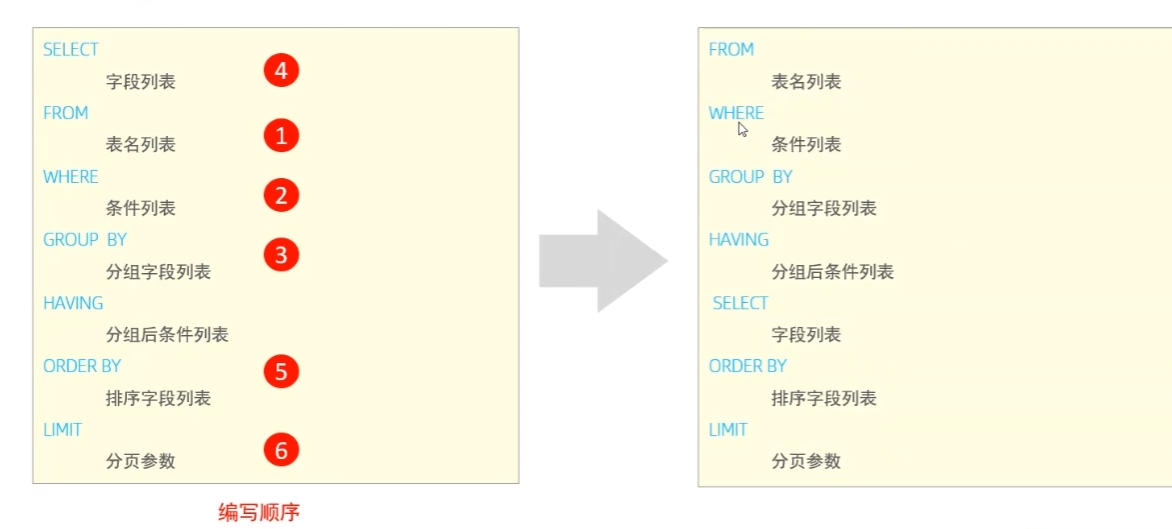
先找表 → 再连表 → 过滤行 → 分组 → 分组过滤 → 选列 → 去重 → 排序 → 限制行数
数据控制语言 DCL
主要管理数据库的用户,控制数据库的访问权限
用户管理

权限控制
权限种类
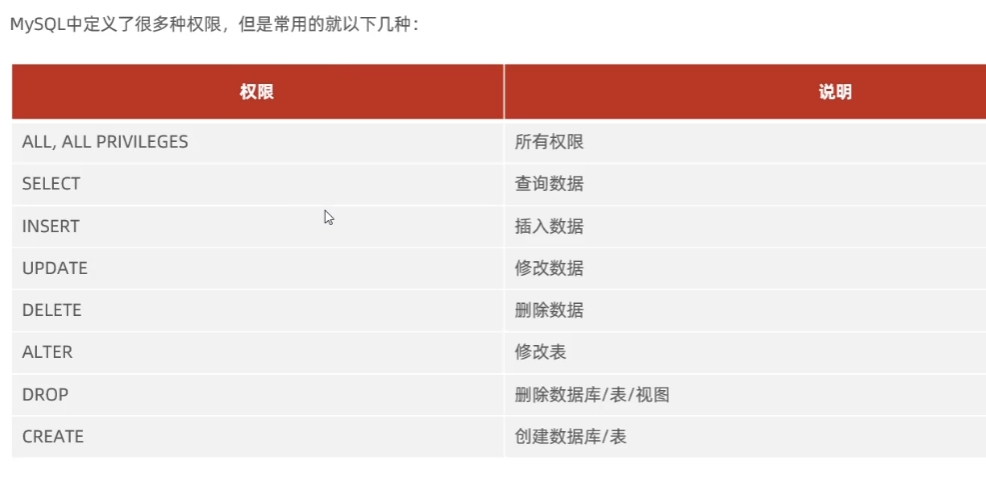
权限控制

WITH GRANT OPTION 决定权限能否继续传播
A → B(WITH GRANT OPTION)
如果 A 给 B 的权限带 WITH GRANT OPTION 则 B 可以继续给 C 授权。
MySQL 权限撤销的级联规则
MySQL 的授权是链式依赖的:
如果某个用户因失去上级权限,不再有授予权,则他授予给其他人的权限会被自动撤销。撤销 A → B 的授权会导致 B 的权限失效,并且 B 曾授予给 C 的权限也会自动被撤销(级联撤销)。
约束

外键约束
外键的定义、添加

外键的删除、更新行为


连接查询
内连接

外连接

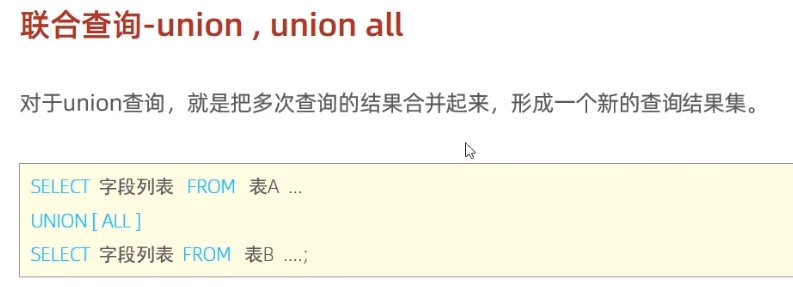
联合查询
子查询

视图

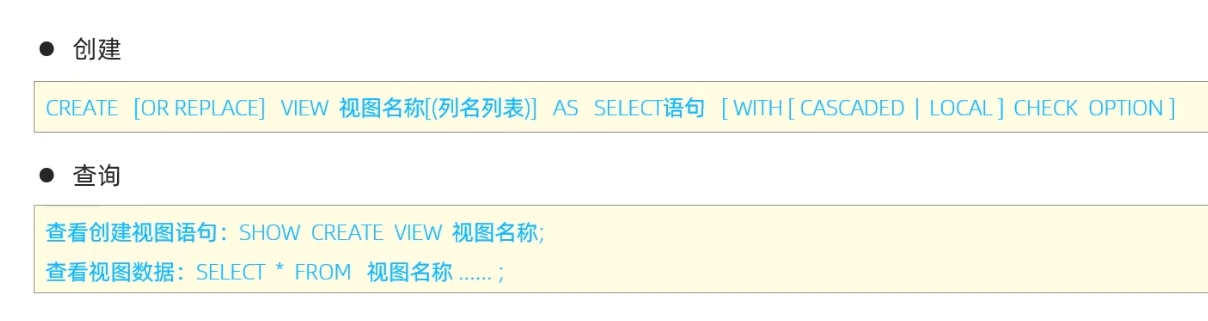



WITH CASCADED CHECK OPTION
严格检查:检查当前视图和所有底层基视图的条件
WITH LOCAL CHECK OPTION
宽松检查:只检查当前视图的条件,不检查底层视图
视图写入时,会检查这个视图的 CHECK OPTION(如果有)。 如果该视图是 CASCADED,则继续检查父视图; 如果是 LOCAL,则不会自动检查父视图。 但是:如果父视图本身也有 CHECK OPTION(无论 Local / Cascaded),写入必定会触发父视图自己的检查。
不管是宽松还是严格,只要with了checkoption,都会触发上一层的检查,由上一层决定后续的检查
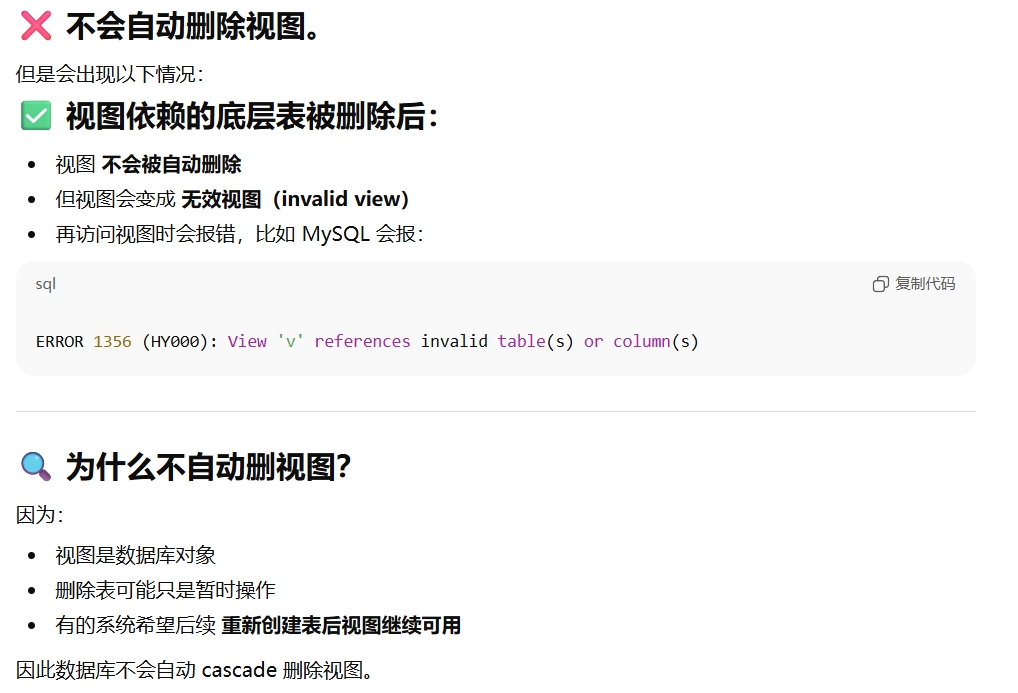
删除表,会删除表上的视图吗(考过)
第四部分 ER模型
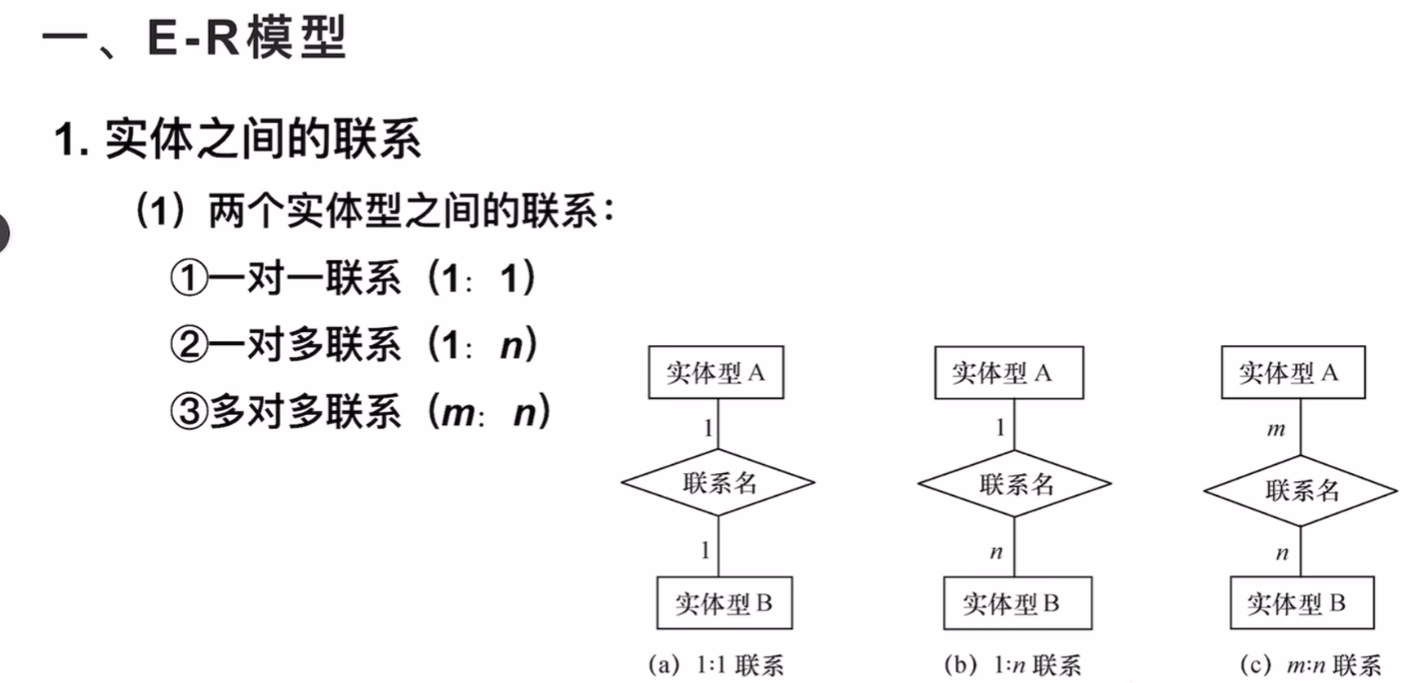
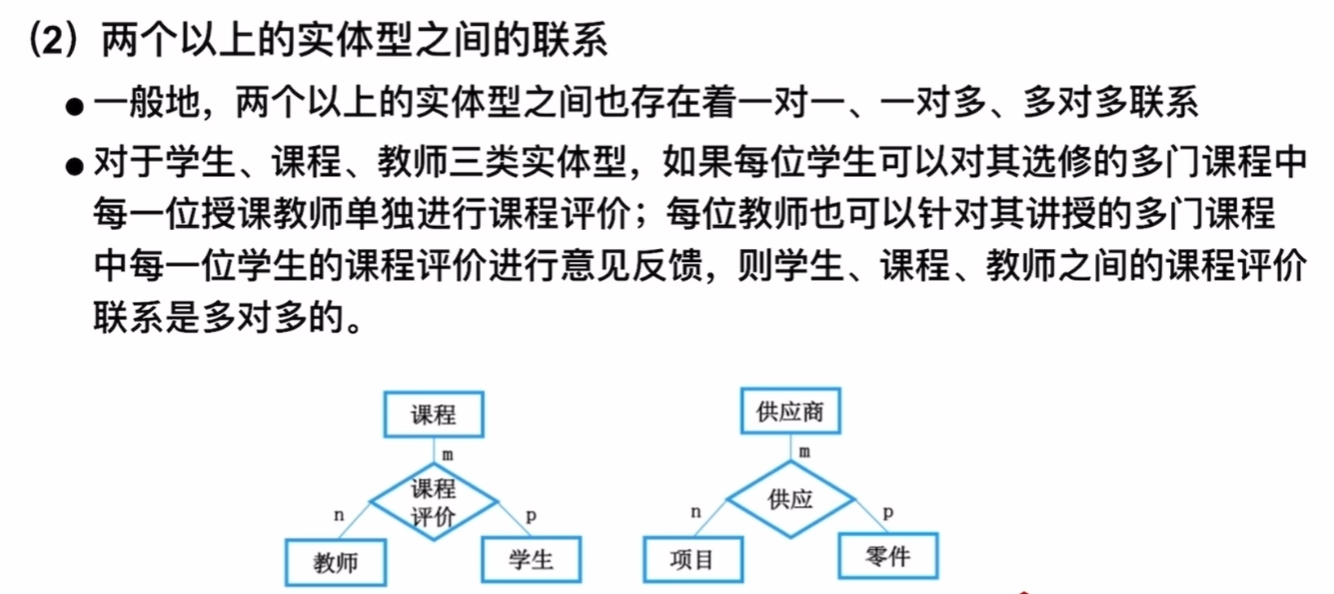
ER模型

ER图中的冲突

第五部分 关系数据库理论
关系的五部分
五元组
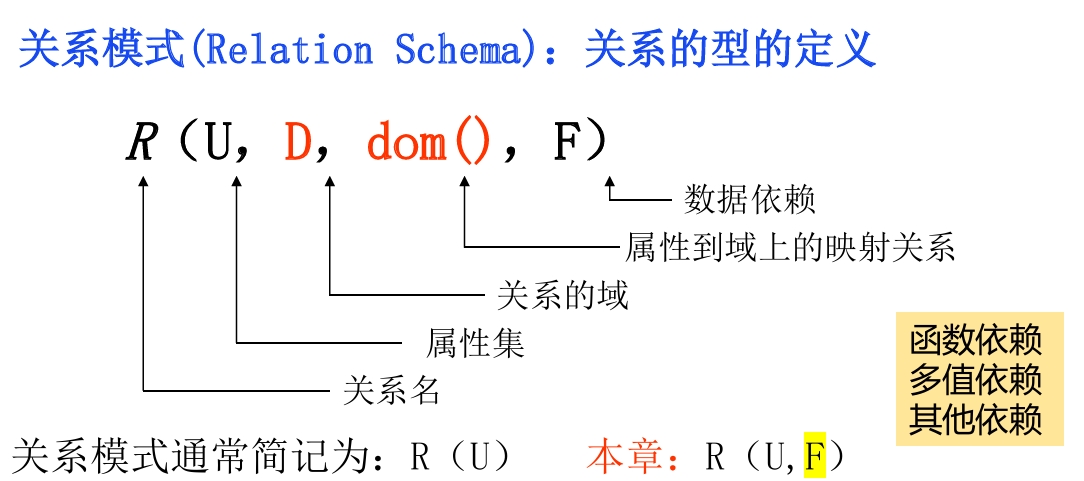
函数依赖

平凡的函数依赖,可以理解为自己推自己,如(A,B)->A,但是A本身就能退出自己,没意义。
部分函数依赖(不完全),(A,B)->C,如果A可以单推C,那这叫做部分函数依赖。
范式
第一范式
每个单元格都不可再分
第二范式
若关系模式R∈1NF,并且每一个非主属性都完全函数依赖于R的码,则R∈2NF
第三范式

即在第二范式的基础上,消除非主属性对主属性的传递函数依赖
BC范式

通常认为,BCNF是3NF的修正与扩充


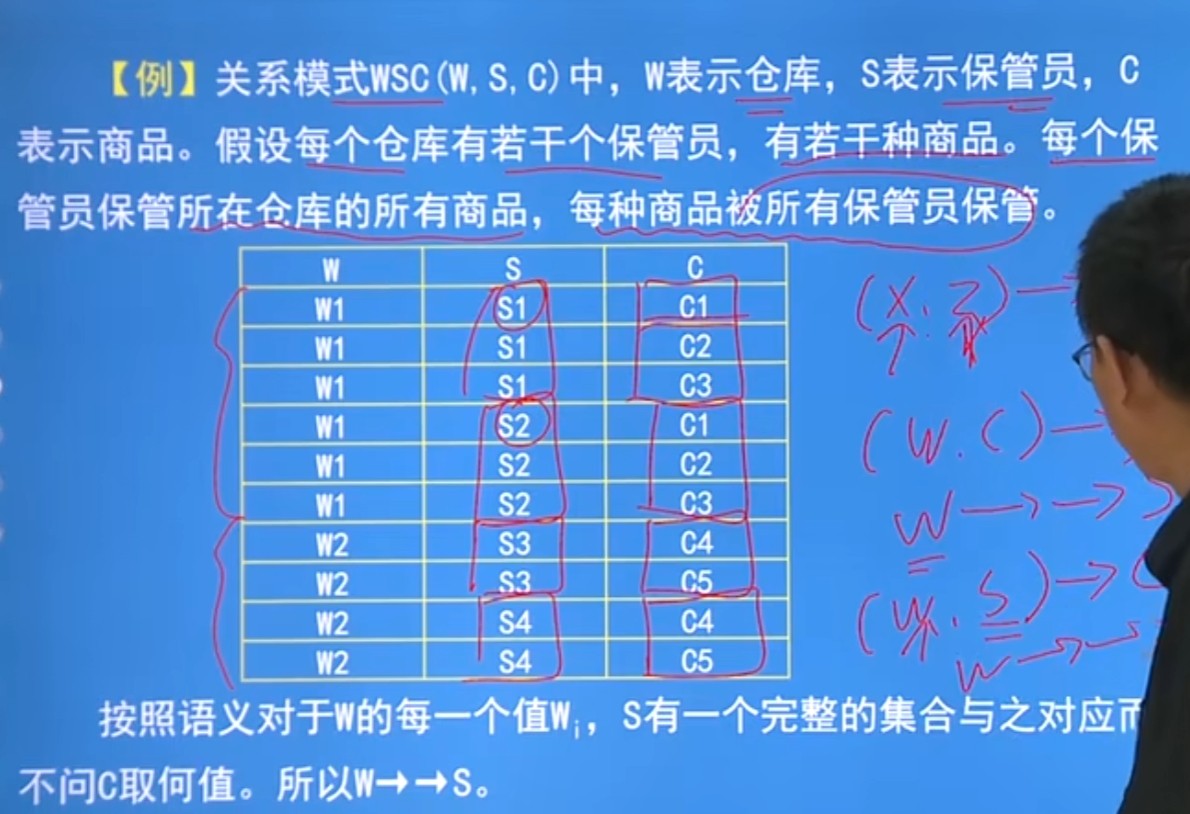
多值依赖

有一组Y的值,把这一组理解为一个集合,一个x值就决定了一个集合,与z无关

如下图:

第四范式

ArmStrong
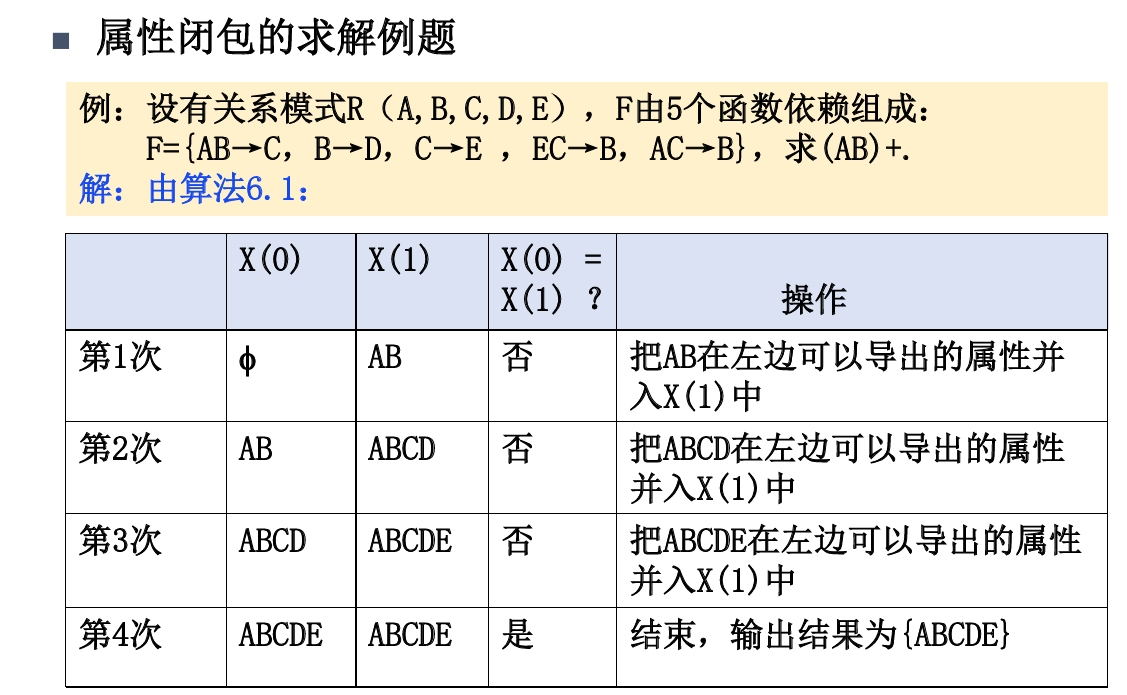
属性闭包
由一组(个)属性,可以推出的所有属性,包括自身。

最小函数依赖集

第一步就是先拆开
第二步的意思是,如果不用加这一条,X也能推A,就可以把这一句废话删掉。
第三步意思是,如果AB就可以推Y,那么ABC->Y就显得冗余了,只要AB->Y就好
求解候选码
属性的分类


L属性不可被别人推,那自己必然就在码中
R只能被别人推,自己谁都推不了
求解方法

候选码必然包含了L、N所以以二者的并为初始
如果一次成功推出了U,就说明成功,直接解释
如果不,就要尝试把LR中的“挪”过来,先一个一个挪,找到能推出U的,就成功结束,不行就两个两个,再不行三个三个......
数据库设计
概述
构造优化的数据库逻辑模式和物理结构,建立数据库及其应用系统
基本步骤
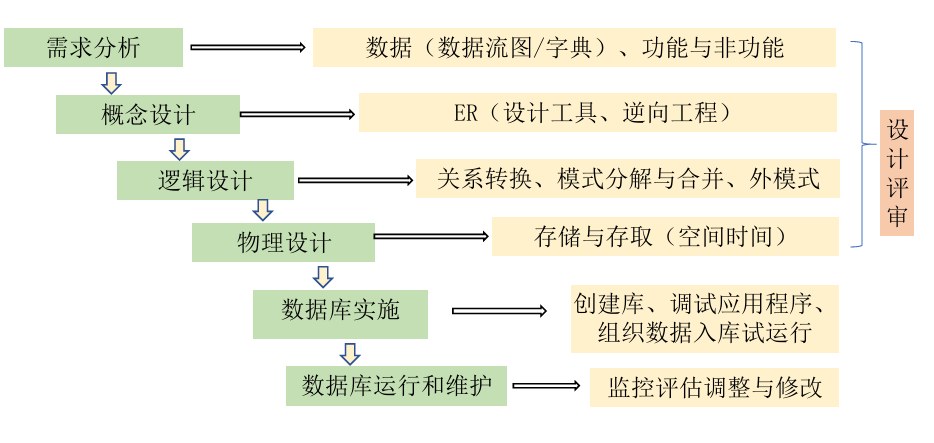
数据库的物理设计
确定数据库存储结构
- 存放位置
- 存储结构 确定数据库存取方法
- 索引方法
- 聚簇方法 聚簇的局限性 1. 聚簇只能提高某些特定应用的性能 2. 建立与维护聚簇的开销相当大 聚簇索引的选择原则 1.对经常进行自然连接的表的连接项建立聚簇 2.对经常做相等比较的属性或属性组建立聚簇 3.对重复率高的属性(组)建立聚簇索引
- HASH 方法 该关系的属性主要出现在等值连接条件中或主要出现在 相等比较选择条件中。
存储管理
数据库的逻辑组织方式:表空间—段—分区—数据块 数据库的物理组织方式:记录——>块——>文件 表空间对应文件,数据块对应物理块
##索引分类 1.稠密索引与稀疏索引 2.聚集索引与非聚集索引 3.主索引与辅助索引 4.全文索引 索引结构 1.B+树索引 2.Hash索引 3.位图索引
数据库恢复技术
原子性 一致性 隔离性 持续性
故障种类
1.事务故障 2.系统故障 3.介质故障
恢复的实现技术
- 数据转储( backup)
- 日志文件(logging) 日志文件的作用 —— 故障恢复必须使用日志文件 事务提交日志 检查点日志 事务回滚日志
系统故障恢复
系统故障造成数据库不一致状态的原因
- 未完成事务:数据可能已经部分写入,但后来的故障导 致这个事务需要终止。
- 已提交事务:日志已经写入磁盘,但对数据库的更新可 能还留在缓冲区没来得及写入磁盘 系统故障恢复方法
- 故障发生时未完成的事务:Undo
- 故障发生时已完成的事务:Redo
并发控制
事务是并发控制的基本单位 并发控制的任务 n 对并发操作进行正确调度 n 保证事务的隔离性 n 保证数据的一致性
丢失修改 T2回滚的结果覆盖了T1提交的结果(第一类错误) T2提交的结果覆盖了T1提交的结果(第二类错误) 脏数据 - T1修改写回,T2读,T1回滚,此时T2读数据为脏数据
不可重复读- T1读,T2更新,T1再次读(与第一次读取数据不同) 该类错误中还包括:幻读(phantom row)- T1读后,T2删除/插入部分记录,T1再读时不同
封锁
基本封锁类型 排他锁 Xlock 共享锁 Slock
封锁协议
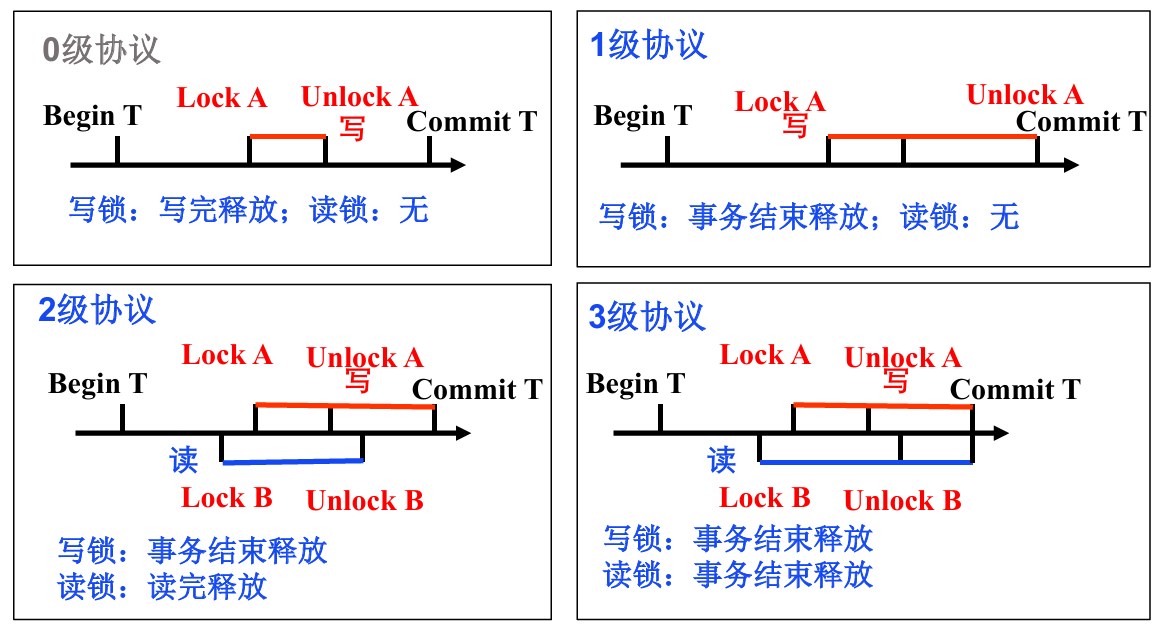 1级:解决修改丢失 2级:解决读脏数据 3级:解决不可重复读
1级:解决修改丢失 2级:解决读脏数据 3级:解决不可重复读
活锁与死锁
活锁解决方案: 依据请求封锁的先 后次序对事务排队, 首先批准申请队列 中第一个事务获得 锁。 死锁解决方案:
- 一次封锁法
- 顺序封锁法
- 超时法
- 等待图法
并发调度的可串行化
将所有事务串行的调度策略一定是正确的调度策略
几个事务的并行执行是正确的,当且仅当其结果与 按某一次序串行地执行它们时的结果相同。
冲突可串行化调度 一个调度Sc在保证冲突操作的次序不变的情况下,通过 交换两个事务不冲突操作的次序得到另一个调度Sc',如 果Sc'是串行的,称调度Sc是冲突可串行化的调度。
两段锁协议
第一阶段是获得封锁,也称为扩展阶段; 第二阶段是释放封锁,也称为收缩阶段。
(1)所有遵守两段锁协议的事务,其并行执行的结果一 定是正确的。 (2)事务遵守两段锁协议是可串行化调度的充分条件, 而不是必要条件
封锁的粒度
- 显式封锁:直接加到数据对象上的封锁
- 隐式封锁:该数据对象没有独立加锁,是由于其上级结点 加锁而使该数据对象加上了锁
意向锁: 如果对一个结点加意向锁,则说明该结点的下层结点正在被加锁 对任一结点加基本锁,必须先对它的上层结点加意向锁
常用意向锁: 意向共享锁 意向排他锁 共享意向排他锁
Re ord Lock :单个行记录上的锁 Gap Lock :间隙锁,锁定一个范围,不包含记录本身 Next-Key Lock:Gap Lock + Record Lock