3DGS简单的本地化部署与使用
从GitHub克隆项目
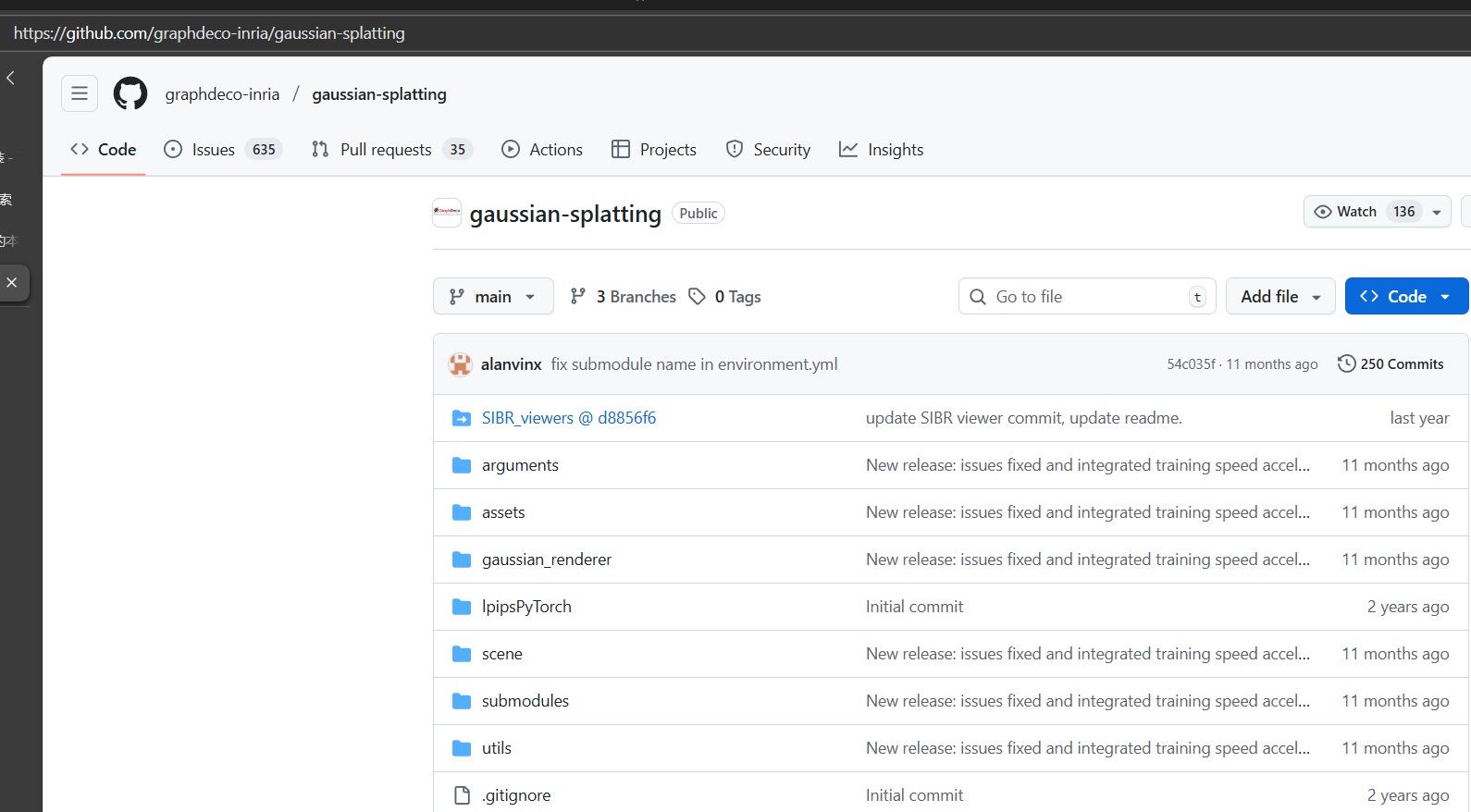
直接到GitHub项目页面看看,克隆即可,这里有一个小坑,就是如果直接下载那个zip包,会缺少submodules文件夹下的内容,所以需要使用克隆指令(看了项目下面的md才知道的),从下面给的文档得知,需要执行 如下命令:
# HTTPS
git clone https://github.com/graphdeco-inria/gaussian-splatting --recursive其实关键在后面的--recursive上,它的作用是,在克隆(clone)一个含有 子模块(submodule) 的仓库时,同时自动把所有子模块也初始化并更新。
环境搭建
对于老显卡,很简单,克隆下来后有一个environment.yml,直接利用那个就可以快速创建一个满足要求的环境。
但是我是较新的显卡(5070),不支持cuda11系列,我是这样安装的,仅供参考:
我把yml改成了下面这个样子:
name: gaussian_splatting
channels:
- conda-forge
- defaults
dependencies:
- plyfile
- python=3.10
- pip=22.3.1
- tqdm
- pip:
# - submodules/diff-gaussian-rasterization
# - submodules/simple-knn
# - submodules/fused-ssim
- opencv-python
- joblib可以看到,我把与pytorch有关的全都删了,但是由于被注释掉的三个是依赖pytorch的,所以我先不装,创建好conda后,我先安装cuda12.8版本的pytorch,以及对应的torchaudio和torchvision,最后再执行的诸如pip install submodules/diff-gaussian-rasterization的三个子模块。我一开始执行的时候不行,更新一下pip就好了。
安装colmap
为啥要装这个呢,因为从readme中得知,train.py需要的其实是经过colmap处理过的数据来训练的:  到colmap的release页面,下载对应的版本(总得有cuda叭):
到colmap的release页面,下载对应的版本(总得有cuda叭): 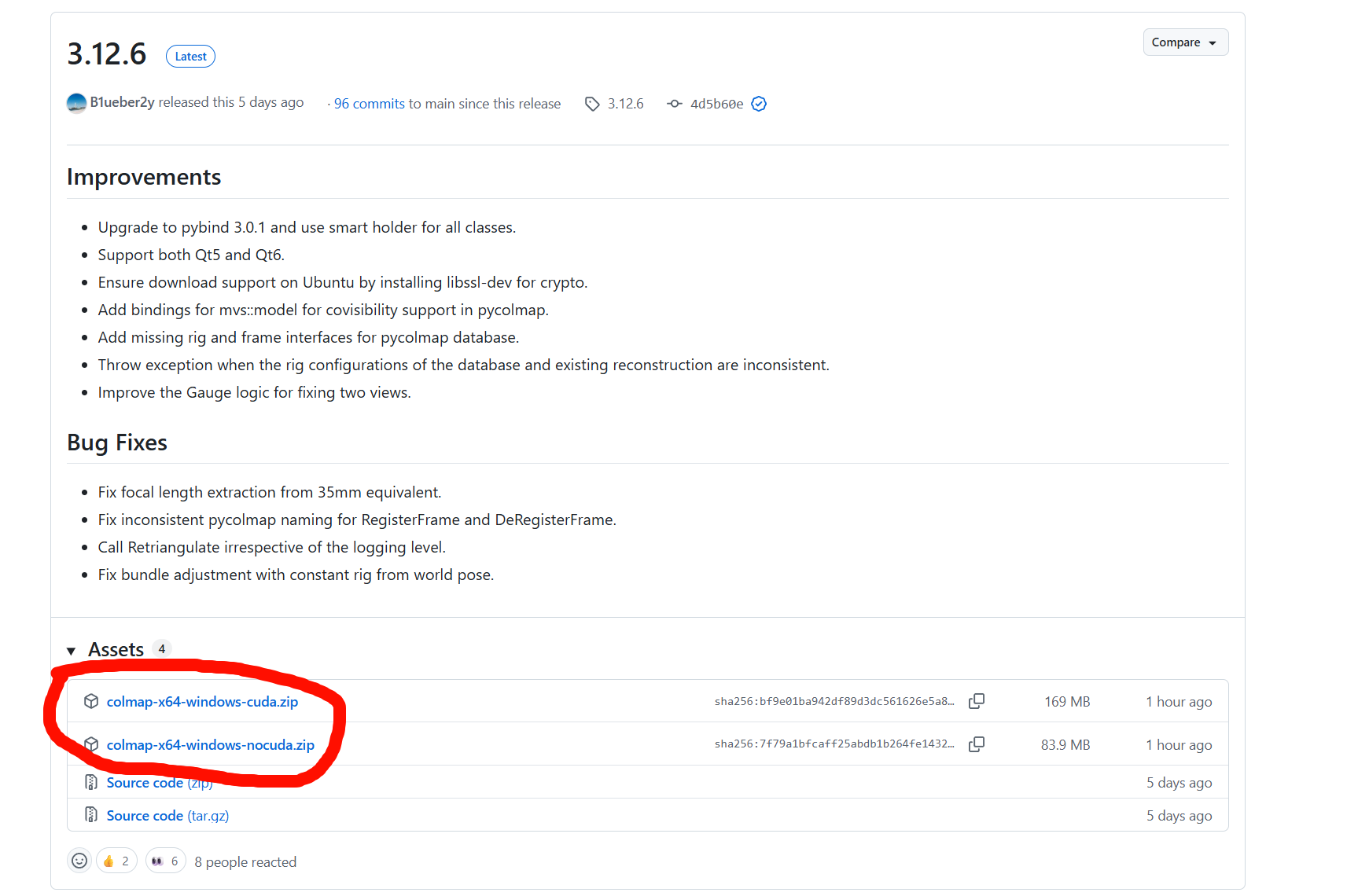
下载之后,解压到一个位置,你想装在哪就解压到哪,然后把其下的\bin文件夹加到环境变量path,为什么要这样呢,因为后面用convert.py的时候,里面有这么一个代码:  当我们不指定colmap位置时,会直接执行colmap命令,即从环境变量中扫,这样更方便。
当我们不指定colmap位置时,会直接执行colmap命令,即从环境变量中扫,这样更方便。
图像数据准备
创建一个data(这里不叫data也可以)文件夹在项目下,然后再在data下创建一个input文件夹,注意,这里必须叫input,然后把你的训练用的图片扔里面就可以了。
数据预处理
执行python convert.py -s data, 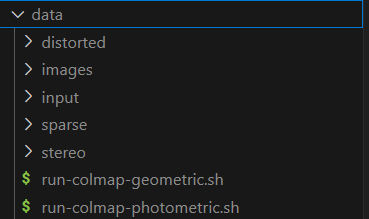 之后,可以发现,在你的data文件夹下,多了好多文件,不用管,这样就可以了。
之后,可以发现,在你的data文件夹下,多了好多文件,不用管,这样就可以了。
训练
执行python train.py -s data, 如果顺利执行,就没事, 但是如果报我这种错:
OMP: Error #15: Initializing libomp.dll, but found libiomp5md.dll already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program. That is dangerous, since it can degrade performance or cause incorrect results. The best thing to do is to ensure that only a single OpenMP runtime is linked into the process, e.g. by avoiding static linking of the OpenMP runtime in any library. As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results. For more information, please see http://openmp.llvm.org/也不用慌,我估摸着是我环境创建yml中已经安装了一些库,比如numpy,我随后手动安装pytorch还有那些子模块时,有的可能重复,只要在执行train命令前,执行: $env:KMP_DUPLICATE_LIB_OK="TRUE"
就可以了,查阅资料得,作用是允许同一个进程里加载多个 OpenMP 运行时库副本。
查看结果
训练后,默认是一共3万轮,在第7000轮时,会先给你一个ply,在/output/巴拉巴拉/point_cloud/iteration_xxx/point_cloud.ply
那么如何查看那种3d重建的结果呢,其实官方也有查看工具,但是我感觉那个麻烦,用起来也难受,这里推荐老师上课说的那个网站:https://superspl.at/
进入后,点击左上方图标右边有一个editor,然后文件-导入,导入你的ply即可。 剩下功能自己摸索,可以说是很全。我一般先把方向挪正,再用那个盒选择工具选中我的主体,然后选择-反选,这样可以选中不要的东西删除,最后导出的时候,有一个是“查看器应用”, 这个很牛逼,可以直接导出为html,点击就能看。 